
Ever wondered about the difference between Artificial Intelligence, Machine Learning and Data Science? Well then this article may shed some light. We will take a look at some definitions, further explanations, use cases and tools to get you started.
Artificial Intelligence

Artificial Intelligence or AI is a very broad term which includes some topics such as Machine Learning, Robotics, Computer Vision, Natural Language Processing, etc. On this IBM Page – which also gives a brief overview of the history of AI – we can find the following definition regarding Artificial Intelligence:
Artificial intelligence leverages computers and machines to mimic the problem-solving and decision-making capabilities of the human mind.
IBM
Or with other words you could also say: To imitate human capabilities with computers.
You can also differentiate between Weak AI or Narrow AI — which is AI trained and focused to perform specific tasks, like a simple prediction of a class or value — and on the other hand Strong AI or General AI — which is a theoretical form of AI where the AI has an intelligence equal to humans with a self-aware consciousness and the ability to solve problems, learn, and plan for the future.
Machine Learning
Now we already learned that Machine Learning is one of many sub-fields of Artificial Intelligence, so let’s take a look at a definition of Machine Learning by Arthur Samuel – one of the pioneers in AI:
Field of study that gives computers the ability to learn without being explicitly programmed.
Arthur samuel
“Explicitly programmed” is when for instance a software engineer writes a series of rules that give instructions on how to transform input data into a desired output. An example is an IF-THEN structure, if a condition is met, a specific action is executed by the software program.
Machine Learning follows a different approach, here no rules are defined, but a machine learns with the help of past observations, or a multitude of examples of labeled data (also called structured or training data) to achieve the desired output.
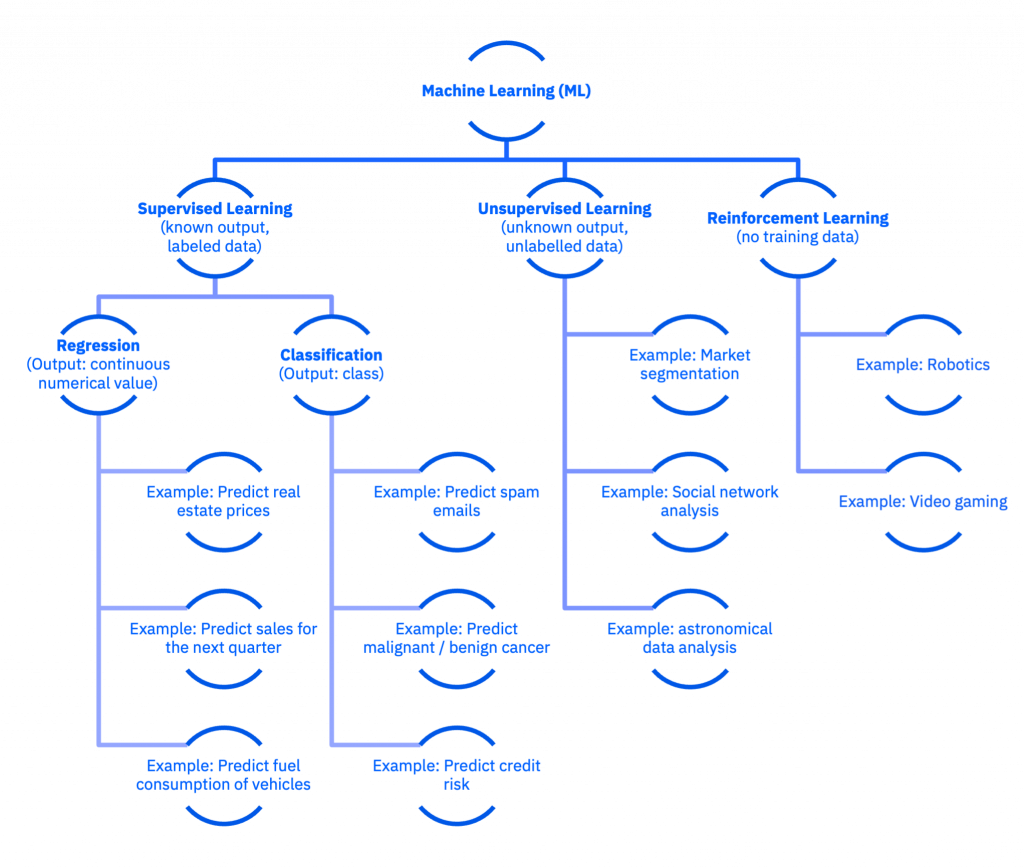
If you look at Machine Learning in further detail we can divide it into several types of Machine Learning: Supervised Machine Learning, Unsupervised Machine Learning, Reinforcement Learning and Deep Learning.
Supervised Machine Learning
Supervised ML uses labeled training data to make predictions. Each sample in the labeled training data contains labeled input data and a desired (and known) output. The supervised learning algorithm uses all of these samples to learn. After the training the supervised learning algorithm will be able to determine the output for unseen labeled input data.
Supervised Machine Learning is the most common and popular approach to ML. It is “supervised”, because it uses manually labeled data to learn from. Therefore, a human basically decides what data the model should use in order to find patterns and predict outputs.
Supervised Machine Learning can be further divided into two types of supervised learning tasks:
- Classification: The desired output value is a class with 2 or more options. Use cases for classification are predicting spam emails, malignant or benign skin lesions – which would both be binary classifications (true or false) – or credit risk.
- Regression: The desired output value is a continuous number. Use cases for regression are predicting real estate prices, sales volumes for the next quarter or fuel consumption of vehicles.
Unsupervised Machine Learning
Unsupervised ML uses unlabelled training data to uncover insights and relationships. In this case, input data is also available but the desired output is unknown. Therefore, models are not trained with the “right output or answer,” hence they must find patterns on their own.
The most common task of unsupervised learning is clustering, which is basically to group similar data. This method is helpful for exploratory analysis to detect hidden patterns or trends. Use cases are clustering data for market segmentation, social network analysis or astronomical data analysis.
Reinforcement Learning
Reinforcement Learning does not use any training data, but rather learns by trial and error. The intention is to find the “best possible path” for a given situation or problem. The machines learn from their own mistakes and choose or reinforce actions that lead to the best possible solution.
Reinforcement Learning is mostly applied for use cases in robotics and video gaming, due to a clear correlation between actions and results.
Deep Learning
Deep Learning can be supervised or unsupervised, or a combination of both. Deep Learning is based on neural networks (NN), with more than three layers of interconnected neurons. Furthermore, Deep Learning automates many of the manual human intervention tasks, enabling it to use much larger data sets. In general it performs much better than other machine learning algorithms on complex problems that require massive sets of data. However, it also often takes a lot of time to train them.
Data Science
At this moment we know what Artificial Intelligence is and we also know what Machine Learning is, but how comes Data Science into play?
Well here is a definition of Data Science according to Wikipedia:
Interdisciplinary field to extract knowledge and insights from structured and unstructured data.
Wikipedia
Interdisciplinary refers to working between multiple disciplines, or having touch points with multiple disciplines, such as computer science, statistics & mathematics, as well as domain knowledge & business know-how. You will need these disciplines to get knowledge and insights from your data.
Data Science deals with:
- the analysis of (large) amounts of data,
- the identification of anomalies in the data,
- as well as with the prediction of future events.
If we take a closer look at the 3rd bullet point “the prediction of future events”, the aim of that could be to provide recommended actions, or improved decision making, or simply to optimize and automate processes. This means that Data Science is closely related to Machine Learning, because with data you can build ML models to automate processes like spam detection, recommended actions for high credit risk, or improved decision making when we know the predicted sales volume of the next quarter.
How to get started?
A great way to get started is by using the platform IBM Cloud Pak for Data as a Service, there you can explore the tutorials, resources, and tools to immediately get started, for instance with preparing, analyzing and visualizing data as well as building and deploying ML models.